Trying out the support vector machine algorithm on the stellar-classification dataset, to successfully predict the target variable.
Preprocess the Data
Code
# import the required librariesimport pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport matplotlib.patches as mpatchesfrom sklearn.svm import SVCfrom sklearn.metrics import accuracy_scorefrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import StandardScalerfrom sklearn.compose import ColumnTransformerfrom sklearn.compose import make_column_selector as selectorfrom sklearn.preprocessing import PowerTransformerfrom sklearn.pipeline import Pipelinefrom sklearn.preprocessing import OneHotEncoderimport tensorflow as tf
Code
# load in the dataset# note: uncomment the following lines to download the dataset# !kaggle datasets download -d fedesoriano/stellar-classification-dataset-sdss17# !unzip stellar-classification-dataset-sdss17.zip# !rm stellar-classification-dataset-sdss17.zip# !echo 'Dataset Downloaded Successfully'
Code
# read in the datasetstellar = pd.read_csv("star_classification.csv")stellar.head()
obj_ID
alpha
delta
u
g
r
i
z
run_ID
rerun_ID
cam_col
field_ID
spec_obj_ID
class
redshift
plate
MJD
fiber_ID
0
1.237661e+18
135.689107
32.494632
23.87882
22.27530
20.39501
19.16573
18.79371
3606
301
2
79
6.543777e+18
GALAXY
0.634794
5812
56354
171
1
1.237665e+18
144.826101
31.274185
24.77759
22.83188
22.58444
21.16812
21.61427
4518
301
5
119
1.176014e+19
GALAXY
0.779136
10445
58158
427
2
1.237661e+18
142.188790
35.582444
25.26307
22.66389
20.60976
19.34857
18.94827
3606
301
2
120
5.152200e+18
GALAXY
0.644195
4576
55592
299
3
1.237663e+18
338.741038
-0.402828
22.13682
23.77656
21.61162
20.50454
19.25010
4192
301
3
214
1.030107e+19
GALAXY
0.932346
9149
58039
775
4
1.237680e+18
345.282593
21.183866
19.43718
17.58028
16.49747
15.97711
15.54461
8102
301
3
137
6.891865e+18
GALAXY
0.116123
6121
56187
842
Code
# statistical overview of the datasetstellar.info()
We see that there are 3 values for our traget variable class, namely:
GALAXY
QSO
START
Code
# number of observationslen(stellar)
100000
Code
# reorder the observations based on the class variablestellar.sort_values('class', axis=0, ascending=True, inplace=True)
Code
# distribution of the classe's observations# view the layout of the datasetresult = {}target_labels = stellar['class'].tolist()for target in target_labels: result[target] =-1for index, obs inenumerate(stellar.values):if result[obs[13]] ==-1: result[obs[13]] = indexresult
{'GALAXY': 0, 'QSO': 59445, 'STAR': 78406}
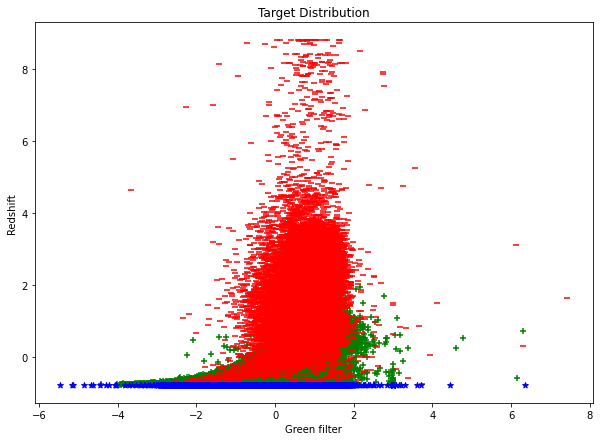
We can now proceed to viewing the distribution of each class in a plot
Code
# visualize using the features: `redshift` and `alpha`class_labels = stellar['class']scaled_features = StandardScaler().fit_transform(stellar.drop('class', axis=1))scaled_stellar = pd.DataFrame(scaled_features, index=stellar.index, columns=(stellar.drop('class', axis=1)).columns)scaled_stellar['class'] = class_labelsscaled_stellar
# encode values for class columnstellar.replace({'class': {'GALAXY': 0, 'STAR': 1, 'QSO':2}}, inplace=True)# remove all columns containing ID at the endcleaned = stellar.drop(stellar.filter(regex='ID$').columns, axis=1)# drop the date columncleaned = stellar.drop('MJD', axis=1)
Code
# make the X and y varialbes (all features)X_all = cleaned.drop('class', axis=1)y = cleaned['class']
Code
# keep the 2 featuresfeatures = cleaned.columns.tolist()features.remove('redshift')features.remove('g')# make the X and y varialbesX_specifc = cleaned.drop(features, axis=1)
# initialize an SVC model (all features)X_train, X_test, y_train, y_test = train_test_split(X_all, y, train_size=0.7, random_state=123)svc_clf = SVC(kernel='rbf')svc_model_pipeline = Pipeline(steps=[ ("preprocessor", preprocessor), ("model", svc_clf),])# train the model on our datasetsvc_model_pipeline.fit(X_train,y_train)# store the predictions of the modely_pred = svc_model_pipeline.predict(X_test)# evaluate the model on accuracyprint(accuracy_score(y_test,y_pred))
Code
# initialize an SVC model (2 features)X_train, X_test, y_train, y_test = train_test_split(X_specifc, y, train_size=0.7, random_state=123)svc_clf = SVC(kernel='rbf')# train the model on our datasetsvc_model_pipeline = Pipeline(steps=[ ("preprocessor", preprocessor), ("model", svc_clf),])svc_model_pipeline.fit(X_train,y_train)# store the predictions of the modely_pred = svc_model_pipeline.predict(X_test)# evaluate the model on accuracyprint(accuracy_score(y_test,y_pred))
0.9644666666666667
Code
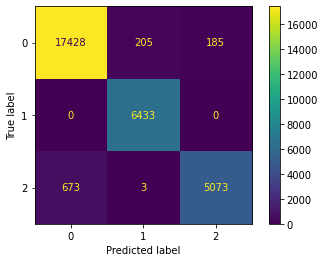
from sklearn.metrics import ConfusionMatrixDisplayConfusionMatrixDisplay.from_predictions(y_test, y_pred)
<sklearn.metrics._plot.confusion_matrix.ConfusionMatrixDisplay at 0x14560f730>
Code
# {'class': {'GALAXY': 0, 'STAR': 1, 'QSO':2}}
array([0, 2, 1])
Using Deep Learning
Code
# re-read in the datasetstellar = pd.read_csv("star_classification.csv")stellar.head()
obj_ID
alpha
delta
u
g
r
i
z
run_ID
rerun_ID
cam_col
field_ID
spec_obj_ID
class
redshift
plate
MJD
fiber_ID
0
1.237661e+18
135.689107
32.494632
23.87882
22.27530
20.39501
19.16573
18.79371
3606
301
2
79
6.543777e+18
GALAXY
0.634794
5812
56354
171
1
1.237665e+18
144.826101
31.274185
24.77759
22.83188
22.58444
21.16812
21.61427
4518
301
5
119
1.176014e+19
GALAXY
0.779136
10445
58158
427
2
1.237661e+18
142.188790
35.582444
25.26307
22.66389
20.60976
19.34857
18.94827
3606
301
2
120
5.152200e+18
GALAXY
0.644195
4576
55592
299
3
1.237663e+18
338.741038
-0.402828
22.13682
23.77656
21.61162
20.50454
19.25010
4192
301
3
214
1.030107e+19
GALAXY
0.932346
9149
58039
775
4
1.237680e+18
345.282593
21.183866
19.43718
17.58028
16.49747
15.97711
15.54461
8102
301
3
137
6.891865e+18
GALAXY
0.116123
6121
56187
842
Feature Engineering
Code
# encode values for class columnstellar.replace({'class': {'GALAXY': 0, 'STAR': 1, 'QSO':2}}, inplace=True)# remove all columns containing ID at the endcleaned = stellar.drop(stellar.filter(regex='ID$').columns, axis=1)# drop the date columncleaned = cleaned.drop('MJD', axis=1)# make the X and y varialbesX = cleaned.drop(['class'], axis=1)y = cleaned['class']# split the datasetX_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.7, random_state=123)
# compile the modeldeep_model.compile( loss='sparse_categorical_crossentropy', optimizer= tf.keras.optimizers.SGD(), metrics= ['accuracy'])
Code
# create the pipelinedeep_model_pipeline = Pipeline(steps=[ ("preprocessor", preprocessor), ("model", deep_model),])
Code
deep_model_pipeline
Pipeline(steps=[('preprocessor',
ColumnTransformer(transformers=[('normalization',
PowerTransformer(),
<sklearn.compose._column_transformer.make_column_selector object at 0x148b62980>),
('standardization',
StandardScaler(),
<sklearn.compose._column_transformer.make_column_selector object at 0x148b61b40>)])),
('model',
<keras.engine.sequential.Sequential object at 0x148b61ab0>)])
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Pipeline(steps=[('preprocessor',
ColumnTransformer(transformers=[('normalization',
PowerTransformer(),
<sklearn.compose._column_transformer.make_column_selector object at 0x148b62980>),
('standardization',
StandardScaler(),
<sklearn.compose._column_transformer.make_column_selector object at 0x148b61b40>)])),
('model',
<keras.engine.sequential.Sequential object at 0x148b61ab0>)])
ColumnTransformer(transformers=[('normalization', PowerTransformer(),
<sklearn.compose._column_transformer.make_column_selector object at 0x148b62980>),
('standardization', StandardScaler(),
<sklearn.compose._column_transformer.make_column_selector object at 0x148b61b40>)])
<sklearn.compose._column_transformer.make_column_selector object at 0x148b62980>
PowerTransformer()
<sklearn.compose._column_transformer.make_column_selector object at 0x148b61b40>
StandardScaler()
<keras.engine.sequential.Sequential object at 0x148b61ab0>