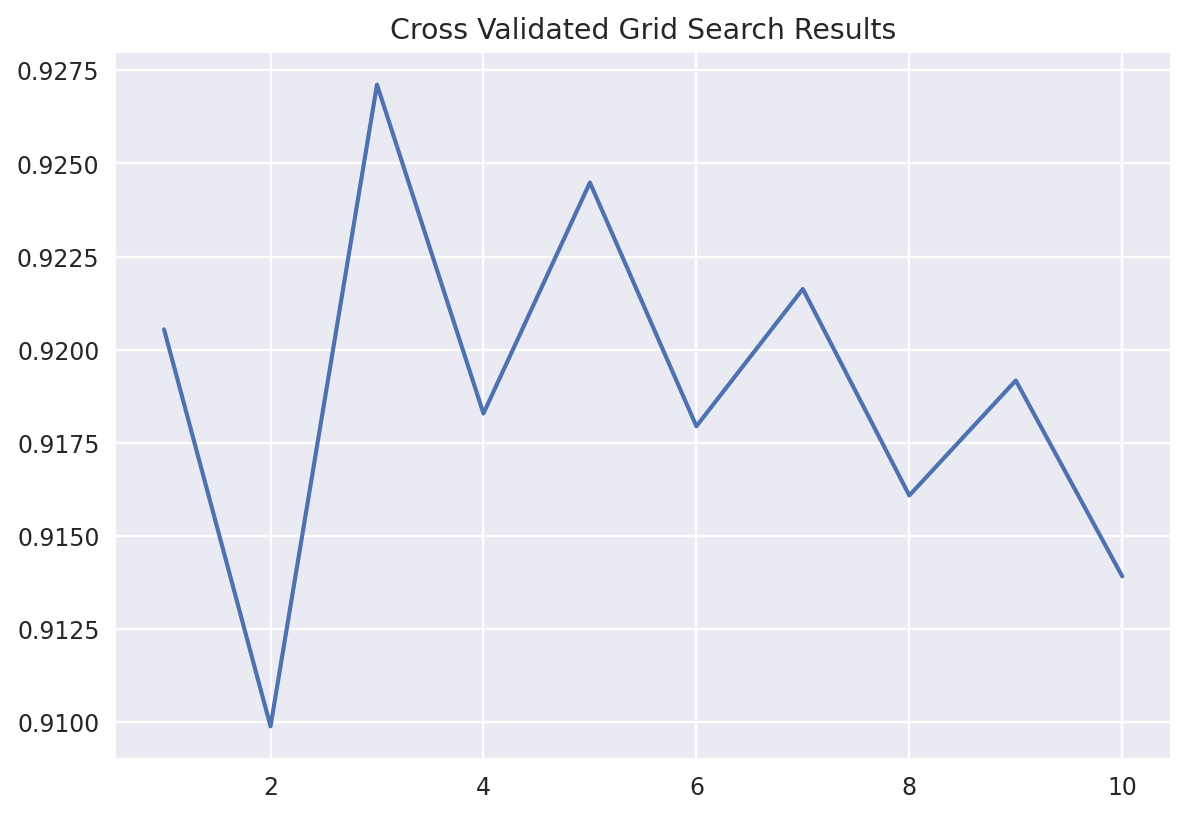
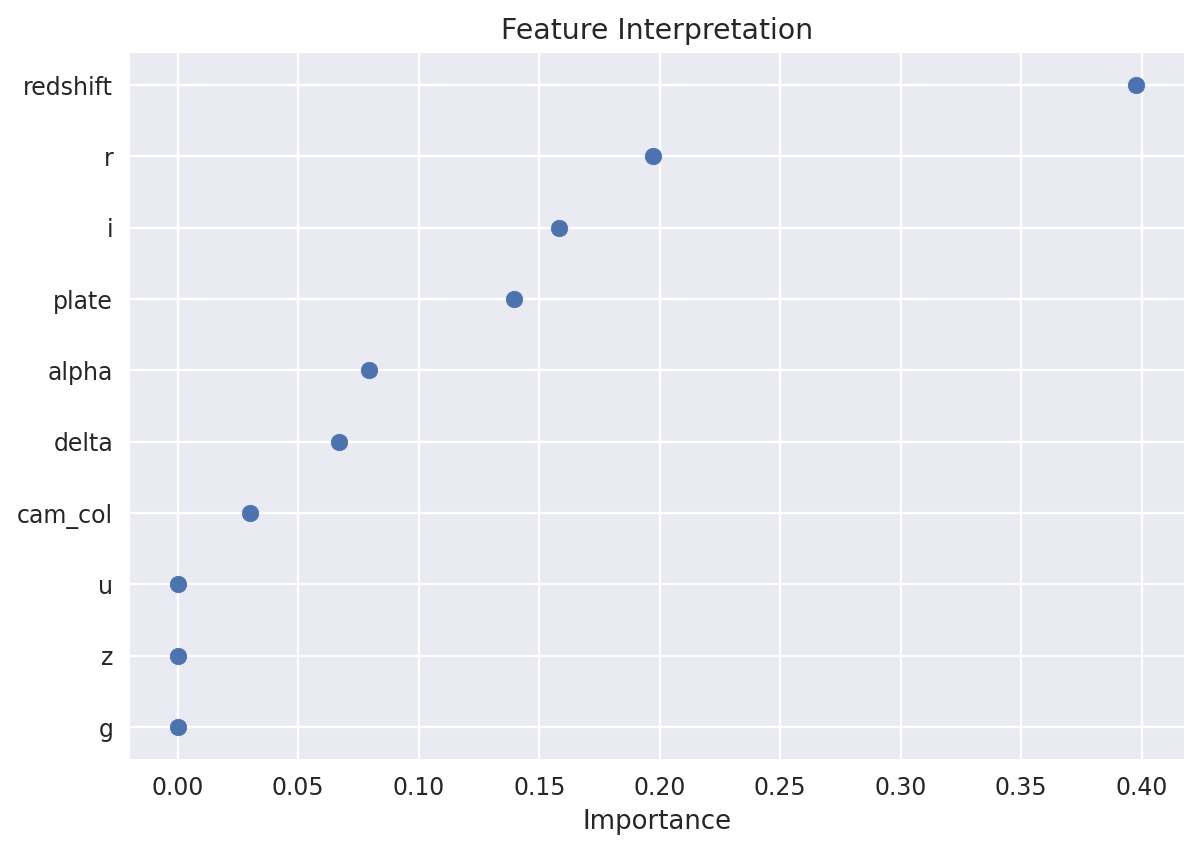
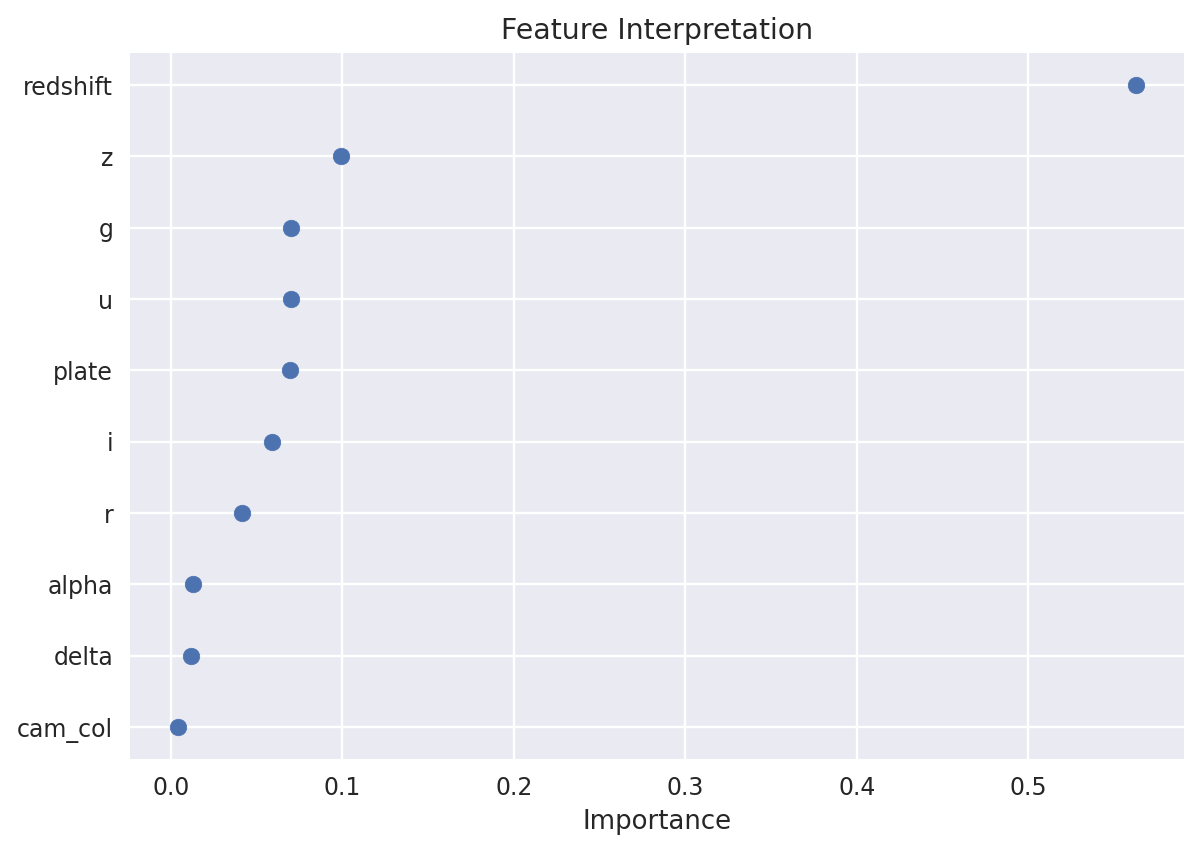
Code
scaler = StandardScaler()
# standardize all columns
X_train_std = scaler.fit_transform(X_train)
# create KNN model
knn = KNeighborsClassifier(n_neighbors=5)
# create 5-Fold CV
kfold = RepeatedStratifiedKFold(n_splits=5,random_state=123)
# Fit the model
results = cross_val_score(knn, X_train_std, y_train, cv=kfold, scoring='accuracy')
print(max(results))0.9341875