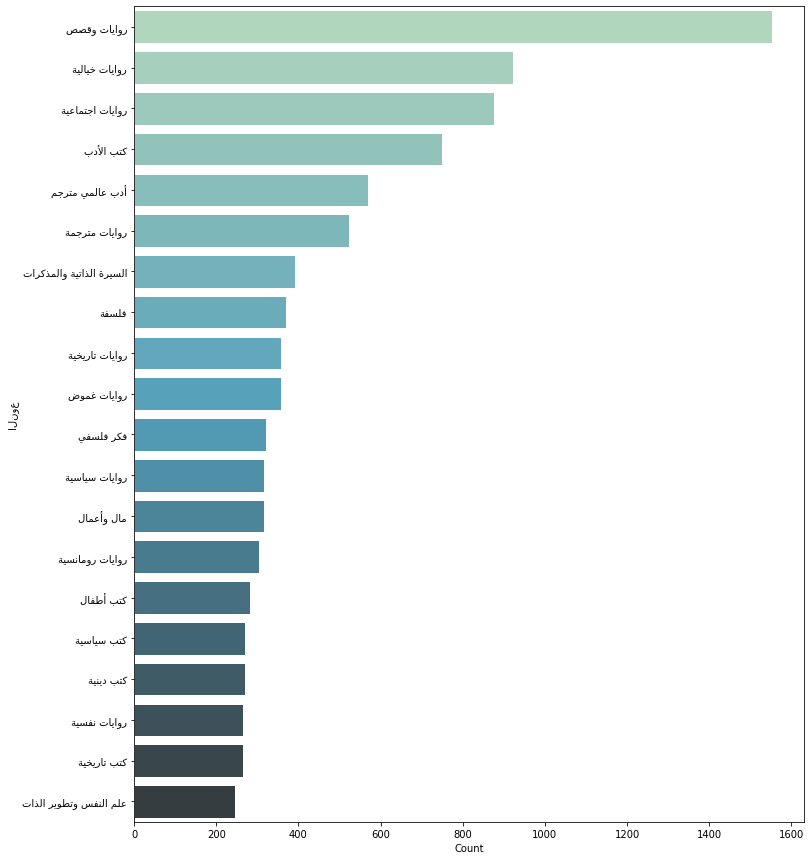
['روايات وقصص', 'روايات رومانسية', 'روايات خيالية', 'روايات اجتماعية', 'روايات واقعية', 'كتب الأدب', 'أدب عالمي مترجم', 'روايات تاريخية', 'روايات فلسفية', 'روايات مترجمة', 'روايات دينية', 'روايات روحانية', 'قصص قصيرة', 'روايات مغامرات', 'روايات رعب', 'روايات فانتازيا', 'روايات نفسية', 'روايات غموض', 'روايات سياسية', 'روايات وطنية', 'روايات الحرب', 'روايات بوليسية', 'روايات خيال علمي', 'روايات ديستوبيا', 'روايات أدب السجون', 'روايات وقصص ساخرة', 'أدب ساخر', 'روايات', 'روايات لليافعين', 'كتب تاريخية', 'التاريخ العربي والإسلامي', 'كتب دينية', 'كتب إسلامية', 'فلسفة وتاريخ أديان', 'الحضارات القديمة', 'دواوين شعر', 'ميثولوجيا وأساطير', 'أساطير', 'دراسات تاريخية', 'تاريخ مصر', 'تاريخ أوروبا', 'نقد أدبي', 'دراسات ومقالات أدبية', 'أمثال ونوادر', 'لغات', 'اللغة العربية', 'دراسات لغوية', 'مسرحيات', 'كتب عن المسيحية', 'الخليج العربي', 'الرياضة والتسلية', 'تسلية وترفيه', 'الشرق الأوسط', 'الصحافة والإعلام', 'الصحافة', 'علم النفس وتطوير الذات', 'علم النفس', 'مقارنات أديان', 'نصوص إبداعية', 'كتب عن اليهودية', 'قانون', 'القضاء', 'رياضات بدنية', 'الترجمة', 'السفر والترحال', 'أدب الرحلات', 'تنمية بشرية وتطوير الذات', 'العادات والتقاليد', 'نثر', 'كتب سياسية', 'فكر سياسي', 'الدين والسياسة', 'مقالات سياسية', 'سياسة عربية', 'المنظمات والأحزاب', 'سياسة دولية', 'كتب قانونية', 'الصراع العربي الإسرائيلي', 'الإعلام', 'الاستشراق', 'تكنولوجيا وإنترنت', 'تكنولوجيا', 'كتب علمية', 'البيئة والطبيعة', 'العلوم', 'علم الاجتماع', 'كمبيوتر وإنترنت', 'الحيوانات', 'السيرة الذاتية والمذكرات', 'كتّاب وأدباء', 'مال وأعمال', 'إدارة الأعمال', 'التسويق', 'ريادة الأعمال', 'الاستثمار', 'الاقتصاد', 'المصارف والبنوك', 'تفسير الأحلام', 'فلاسفة ومفكرون', 'رجال دين', 'ناشطون اجتماعيون', 'فنانون', 'سياسيون', 'روّاد الأعمال', 'رياضيون', 'صحفيون', 'فلسفة', 'فكر فلسفي', 'مقالات فلسفية', 'تاريخ الفلسفة', 'ما وراء الطبيعة', 'المنطق', 'اللسانيات', 'فنون', 'مسرح', 'دراسات فنية', 'مراجع وأبحاث', 'موسوعات', 'لغات أجنبية', 'معاجم', 'أبحاث ودراسات', 'كتب أطفال', 'قصص أطفال', 'كتب تعليمية', 'موسيقى', 'الأسرة والطفل', 'ثقافة جنسية', 'العلاقة الزوجية', 'تنظيم وإدارة المنزل', 'المرأة', 'تربية الطفل', 'الطبخ', 'تصوير', 'عمارة وتصميم', 'فن إسلامي', 'تاريخ الفن', 'سينما', 'الطب والصحة', 'كتب طبية', 'الصحة البدنية', 'الأمراض والأوبئة']
141